概要
sqlglotというSQLのパーサーツールを用いてSQLのパースの内部処理を体験してみました。
SQLパーサーの内部処理は大きく分けて次の3つがあります。
- 字句解析
- 構文解析
- 意味解析
このうち意味解析はSQL中のテーブルが実際にあるか?やユニーク制約が満たされているか?など実際のテーブルの状態と照合する処理なので、SQL文字列のみを対象とするsqlglotは字句解析・構文解析を担当します。
準備
sqlglotを使います。
公式リポジトリで案内されるやり方だと、sqlglotrsも入り、tokenizerにRust実装のものを使うことになり本実験と若干結果(Tokenの構造)が変わってしまうので注意です。
pip install sqlglot==25.23.1
字句解析(Lexical Analysis)
SQL文字列をトークンに分解する処理です。
SELECT name, age FROM users WHERE age > 30;
例えば上記のSQLがあった場合、次のようにトークンが生成されます。
各トークンには、sqlglot内で定められているトークンタイプ(SELECTやVAR, COMMAなど)と、SQLのどの位置で現れるか(line, col, start, end)の情報が載っています。
TokenTypeはenum型でv25.23.1の時点で362種類もあるようです。
[ <Token token_type: TokenType.SELECT, text: SELECT, line: 1, col: 6, start: 0, end: 5, comments: []>, <Token token_type: TokenType.VAR, text: name, line: 1, col: 11, start: 7, end: 10, comments: []>, <Token token_type: TokenType.COMMA, text: ,, line: 1, col: 12, start: 11, end: 11, comments: []>, <Token token_type: TokenType.VAR, text: age, line: 1, col: 16, start: 13, end: 15, comments: []>, <Token token_type: TokenType.FROM, text: FROM, line: 1, col: 21, start: 17, end: 20, comments: []>, <Token token_type: TokenType.VAR, text: users, line: 1, col: 27, start: 22, end: 26, comments: []>, <Token token_type: TokenType.WHERE, text: WHERE, line: 1, col: 33, start: 28, end: 32, comments: []>, <Token token_type: TokenType.VAR, text: age, line: 1, col: 37, start: 34, end: 36, comments: []>, <Token token_type: TokenType.GT, text: >, line: 1, col: 39, start: 38, end: 38, comments: []>, <Token token_type: TokenType.NUMBER, text: 30, line: 1, col: 42, start: 40, end: 41, comments: []>, <Token token_type: TokenType.SEMICOLON, text: ;, line: 1, col: 43, start: 42, end: 42, comments: []> ]
sqlglotではtokenize()でSQL文字列からToken型のリストにする作業を行っているようです。
ちなみにsqlglotrsをインストールしていると、Rustで実装されたTokenizerが働き上記と多少異なる結果になるようです。
github.com
具体的な解析アルゴリズムは_scan()で行っているようです。
github.com
まずSQL文字列全体をwhileで回しつつ、そのループの中でスペースをスキップする処理を入れます。
これによって、ループポインタを空白文字以外の先頭に持ってくる役割をしています。
while current < self.size: char = self.sql[current] if char.isspace() and (char == " " or char == "\t"): current += 1 else: break
次にスキャン対象の位置を更新します。
offset = current - self._current if current > self._current else 1 self._start = current self._advance(offset)
最後に文字の種類に応じた処理を行います。
上から、数値、identifier(カラム名やテーブル名)、SQLキーワード(SELECTやFROMやカンマ)という順でトークナイズされていきます。
各メソッドでは更にTokenTypeというEnum型で分類されていきます。
if not self._char.isspace(): if self._char.isdigit(): self._scan_number() elif self._char in self._IDENTIFIERS: self._scan_identifier(self._IDENTIFIERS[self._char]) else: self._scan_keywords()
下記はClaudeに作ってもらった字句解析の流れを示した図になります。

字句解析では意味までは解釈してません。
そのため、下記のような文字列でも字句解析は通過します。
SELECTTTT SELECT FROM *, *name, age > 4 FROM aaa;
上記SQL(SQLではない)を字句解析に通すと次の結果になります。
[ <Token token_type: TokenType.VAR, text: SELECTTTT, line: 1, col: 9, start: 0, end: 8, comments: []>, <Token token_type: TokenType.SELECT, text: SELECT, line: 1, col: 16, start: 10, end: 15, comments: []>, <Token token_type: TokenType.FROM, text: FROM, line: 1, col: 21, start: 17, end: 20, comments: []>, <Token token_type: TokenType.STAR, text: *, line: 1, col: 23, start: 22, end: 22, comments: []>, <Token token_type: TokenType.COMMA, text: ,, line: 1, col: 24, start: 23, end: 23, comments: []>, <Token token_type: TokenType.STAR, text: *, line: 1, col: 26, start: 25, end: 25, comments: []>, <Token token_type: TokenType.VAR, text: name, line: 1, col: 30, start: 26, end: 29, comments: []>, <Token token_type: TokenType.COMMA, text: ,, line: 1, col: 31, start: 30, end: 30, comments: []>, <Token token_type: TokenType.VAR, text: age, line: 1, col: 35, start: 32, end: 34, comments: []>, <Token token_type: TokenType.GT, text: >, line: 1, col: 37, start: 36, end: 36, comments: []>, <Token token_type: TokenType.NUMBER, text: 4, line: 1, col: 39, start: 38, end: 38, comments: []>, <Token token_type: TokenType.FROM, text: FROM, line: 1, col: 44, start: 40, end: 43, comments: []>, <Token token_type: TokenType.VAR, text: aaa, line: 1, col: 48, start: 45, end: 47, comments: []>, <Token token_type: TokenType.SEMICOLON, text: ;, line: 1, col: 49, start: 48, end: 48, comments: []> ]
構文解析(Syntax Analysis)
構文解析では、字句解析で生成されたトークンと元のSQLを受け取り、SQL文が文法的に正しいかどうかをチェックします。
構文解析はsqlglot/parser.pyの_parser()メソッドで行われています。
github.com
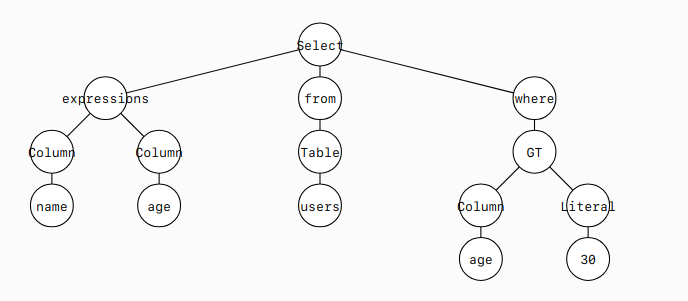
構文解析の結果は次のようになります。
[
Select(
expressions=[
Column(
this=Identifier(this=name, quoted=False)),
Column(
this=Identifier(this=age, quoted=False))
],
from=From(
this=Table(
this=Identifier(this=users, quoted=False)
)
),
where=Where(
this=GT(
this=Column(
this=Identifier(this=age, quoted=False)
),
expression=Literal(this=30, is_string=False)
)
)
)
]
このPythonオブジェクトは下図のような構文木を表しています。
字句解析でエラーにならなかった下記文字列も構文解析ではエラーになります。
SELECTTTT SELECT FROM *, *name, age > 4 FROM aaa;
[ <Token token_type: TokenType.VAR, text: SELECTTTT, line: 1, col: 9, start: 0, end: 8, comments: []>, <Token token_type: TokenType.SELECT, text: SELECT, line: 1, col: 16, start: 10, end: 15, comments: []>, <Token token_type: TokenType.FROM, text: FROM, line: 1, col: 21, start: 17, end: 20, comments: []>, <Token token_type: TokenType.STAR, text: *, line: 1, col: 23, start: 22, end: 22, comments: []>, <Token token_type: TokenType.COMMA, text: ,, line: 1, col: 24, start: 23, end: 23, comments: []>, <Token token_type: TokenType.STAR, text: *, line: 1, col: 26, start: 25, end: 25, comments: []>, <Token token_type: TokenType.VAR, text: name, line: 1, col: 30, start: 26, end: 29, comments: []>, <Token token_type: TokenType.COMMA, text: ,, line: 1, col: 31, start: 30, end: 30, comments: []>, <Token token_type: TokenType.VAR, text: age, line: 1, col: 35, start: 32, end: 34, comments: []>, <Token token_type: TokenType.GT, text: >, line: 1, col: 37, start: 36, end: 36, comments: []>, <Token token_type: TokenType.NUMBER, text: 4, line: 1, col: 39, start: 38, end: 38, comments: []>, <Token token_type: TokenType.FROM, text: FROM, line: 1, col: 44, start: 40, end: 43, comments: []>, <Token token_type: TokenType.VAR, text: aaa, line: 1, col: 48, start: 45, end: 47, comments: []>, <Token token_type: TokenType.SEMICOLON, text: ;, line: 1, col: 49, start: 48, end: 48, comments: []> ]