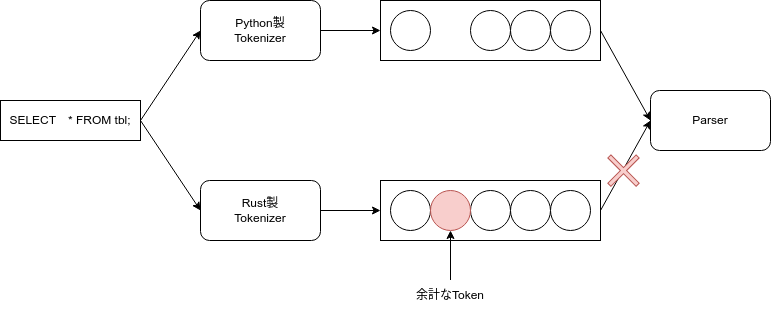
字句解析
字句解析とは、コードを入力として、トークンと呼ばれるコードの最小構成単位のリストに変換する処理です。
この時点ではクラスや関数などPythonコードにおける意味をなす単位でまとまっていません。
字句解析対象のPythonコード
def plus_one(x: int) -> int:
"""引数に1を加えて返す"""
return x + 1
a = 2
plus_one(a)
字句解析を行うPythonコード
import tokenize
with tokenize.open("sample/sample.py") as f:
tokens = tokenize.generate_tokens(f.readline)
for token in tokens:
print(token)
字句解析の結果
TokenInfo(type=1 (NAME), string='def', start=(1, 0), end=(1, 3), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=1 (NAME), string='plus_one', start=(1, 4), end=(1, 12), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=55 (OP), string='(', start=(1, 12), end=(1, 13), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=1 (NAME), string='x', start=(1, 13), end=(1, 14), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=55 (OP), string=':', start=(1, 14), end=(1, 15), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=1 (NAME), string='int', start=(1, 16), end=(1, 19), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=55 (OP), string=')', start=(1, 19), end=(1, 20), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=55 (OP), string='->', start=(1, 21), end=(1, 23), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=1 (NAME), string='int', start=(1, 24), end=(1, 27), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=55 (OP), string=':', start=(1, 27), end=(1, 28), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=4 (NEWLINE), string='\n', start=(1, 28), end=(1, 29), line='def plus_one(x: int) -> int:\n')
TokenInfo(type=5 (INDENT), string=' ', start=(2, 0), end=(2, 4), line=' """引数に1を加えて返す"""\n')
TokenInfo(type=3 (STRING), string='"""引数に1を加えて返す"""', start=(2, 4), end=(2, 20), line=' """引数に1を加えて返す"""\n')
TokenInfo(type=4 (NEWLINE), string='\n', start=(2, 20), end=(2, 21), line=' """引数に1を加えて返す"""\n')
TokenInfo(type=1 (NAME), string='return', start=(3, 4), end=(3, 10), line=' return x + 1\n')
TokenInfo(type=1 (NAME), string='x', start=(3, 11), end=(3, 12), line=' return x + 1\n')
TokenInfo(type=55 (OP), string='+', start=(3, 13), end=(3, 14), line=' return x + 1\n')
TokenInfo(type=2 (NUMBER), string='1', start=(3, 15), end=(3, 16), line=' return x + 1\n')
TokenInfo(type=4 (NEWLINE), string='\n', start=(3, 16), end=(3, 17), line=' return x + 1\n')
TokenInfo(type=63 (NL), string='\n', start=(4, 0), end=(4, 1), line='\n')
TokenInfo(type=63 (NL), string='\n', start=(5, 0), end=(5, 1), line='\n')
TokenInfo(type=6 (DEDENT), string='', start=(6, 0), end=(6, 0), line='a = 2 # aを初期化\n')
TokenInfo(type=1 (NAME), string='a', start=(6, 0), end=(6, 1), line='a = 2 # aを初期化\n')
TokenInfo(type=55 (OP), string='=', start=(6, 2), end=(6, 3), line='a = 2 # aを初期化\n')
TokenInfo(type=2 (NUMBER), string='2', start=(6, 4), end=(6, 5), line='a = 2 # aを初期化\n')
TokenInfo(type=62 (COMMENT), string='# aを初期化', start=(6, 7), end=(6, 14), line='a = 2 # aを初期化\n')
TokenInfo(type=4 (NEWLINE), string='\n', start=(6, 14), end=(6, 15), line='a = 2 # aを初期化\n')
TokenInfo(type=1 (NAME), string='plus_one', start=(7, 0), end=(7, 8), line='plus_one(a) # aに1を加える\n')
TokenInfo(type=55 (OP), string='(', start=(7, 8), end=(7, 9), line='plus_one(a) # aに1を加える\n')
TokenInfo(type=1 (NAME), string='a', start=(7, 9), end=(7, 10), line='plus_one(a) # aに1を加える\n')
TokenInfo(type=55 (OP), string=')', start=(7, 10), end=(7, 11), line='plus_one(a) # aに1を加える\n')
TokenInfo(type=62 (COMMENT), string='# aに1を加える', start=(7, 13), end=(7, 22), line='plus_one(a) # aに1を加える\n')
TokenInfo(type=4 (NEWLINE), string='\n', start=(7, 22), end=(7, 23), line='plus_one(a) # aに1を加える\n')
TokenInfo(type=0 (ENDMARKER), string='', start=(8, 0), end=(8, 0), line='')上記を見ると、各トークンは以下の情報を持っていることがわかります。
- type
- NAME:識別子
- OP:記号
- COMMENT:コメント
- …
- string:トークンが表す文字列
- start:文字列の始まり(y, x)
- end:文字列の終わり(y, x)
- line:トークンが属するPythonコードの1行
各トークンは自身の位置情報を持っているため、このトークン列からソースコードへは逆変換可能です。
また、トークンの状態では、コメント情報も保持されたままであることが分かります。
構文解析
構文解析は入力をトークンリストとし、出力を抽象構文木(AST: Abstract Syntax Tree)とする変換器です。
上記のトークンリストから抽象構文木を作っていきます。
defなどの予約語を解釈して、関数やクラスなどの単位ごとに木を構成していくイメージです。
また、ASTではプログラムの実行に直接関係ないコメントが廃棄されます。
構文解析を行うコード
import ast
def print_ast_nodes(node, indent=0):
"""ASTノードを再帰的に表示する"""
print(
" " * indent
+ f"{type(node).__name__}: {ast.dump(node, annotate_fields=True, include_attributes=True)}"
)
for child in ast.iter_child_nodes(node):
print_ast_nodes(child, indent + 1)
with open("sample/sample.py", "r") as f:
source_code = f.read()
tree = ast.parse(source_code)
print_ast_nodes(tree)
構文解析結果
Module: Module(body=[FunctionDef(name='plus_one', args=arguments(args=[arg(arg='x', annotation=Name(id='int', ctx=Load(), lineno=1, col_offset=16, end_lineno=1, end_col_offset=19), lineno=1, col_offset=13, end_lineno=1, end_col_offset=19)]), body=[Expr(value=Constant(value='引数に1を加えて返す', lineno=2, col_offset=4, end_lineno=2, end_col_offset=38), lineno=2, col_offset=4, end_lineno=2, end_col_offset=38), Return(value=BinOp(left=Name(id='x', ctx=Load(), lineno=3, col_offset=11, end_lineno=3, end_col_offset=12), op=Add(), right=Constant(value=1, lineno=3, col_offset=15, end_lineno=3, end_col_offset=16), lineno=3, col_offset=11, end_lineno=3, end_col_offset=16), lineno=3, col_offset=4, end_lineno=3, end_col_offset=16)], returns=Name(id='int', ctx=Load(), lineno=1, col_offset=24, end_lineno=1, end_col_offset=27), lineno=1, col_offset=0, end_lineno=3, end_col_offset=16), Assign(targets=[Name(id='a', ctx=Store(), lineno=6, col_offset=0, end_lineno=6, end_col_offset=1)], value=Constant(value=2, lineno=6, col_offset=4, end_lineno=6, end_col_offset=5), lineno=6, col_offset=0, end_lineno=6, end_col_offset=5), Expr(value=Call(func=Name(id='plus_one', ctx=Load(), lineno=7, col_offset=0, end_lineno=7, end_col_offset=8), args=[Name(id='a', ctx=Load(), lineno=7, col_offset=9, end_lineno=7, end_col_offset=10)], lineno=7, col_offset=0, end_lineno=7, end_col_offset=11), lineno=7, col_offset=0, end_lineno=7, end_col_offset=11)])
FunctionDef: FunctionDef(name='plus_one', args=arguments(args=[arg(arg='x', annotation=Name(id='int', ctx=Load(), lineno=1, col_offset=16, end_lineno=1, end_col_offset=19), lineno=1, col_offset=13, end_lineno=1, end_col_offset=19)]), body=[Expr(value=Constant(value='引数に1を加えて返す', lineno=2, col_offset=4, end_lineno=2, end_col_offset=38), lineno=2, col_offset=4, end_lineno=2, end_col_offset=38), Return(value=BinOp(left=Name(id='x', ctx=Load(), lineno=3, col_offset=11, end_lineno=3, end_col_offset=12), op=Add(), right=Constant(value=1, lineno=3, col_offset=15, end_lineno=3, end_col_offset=16), lineno=3, col_offset=11, end_lineno=3, end_col_offset=16), lineno=3, col_offset=4, end_lineno=3, end_col_offset=16)], returns=Name(id='int', ctx=Load(), lineno=1, col_offset=24, end_lineno=1, end_col_offset=27), lineno=1, col_offset=0, end_lineno=3, end_col_offset=16)
arguments: arguments(args=[arg(arg='x', annotation=Name(id='int', ctx=Load(), lineno=1, col_offset=16, end_lineno=1, end_col_offset=19), lineno=1, col_offset=13, end_lineno=1, end_col_offset=19)])
arg: arg(arg='x', annotation=Name(id='int', ctx=Load(), lineno=1, col_offset=16, end_lineno=1, end_col_offset=19), lineno=1, col_offset=13, end_lineno=1, end_col_offset=19)
Name: Name(id='int', ctx=Load(), lineno=1, col_offset=16, end_lineno=1, end_col_offset=19)
Load: Load()
Expr: Expr(value=Constant(value='引数に1を加えて返す', lineno=2, col_offset=4, end_lineno=2, end_col_offset=38), lineno=2, col_offset=4, end_lineno=2, end_col_offset=38)
Constant: Constant(value='引数に1を加えて返す', lineno=2, col_offset=4, end_lineno=2, end_col_offset=38)
Return: Return(value=BinOp(left=Name(id='x', ctx=Load(), lineno=3, col_offset=11, end_lineno=3, end_col_offset=12), op=Add(), right=Constant(value=1, lineno=3, col_offset=15, end_lineno=3, end_col_offset=16), lineno=3, col_offset=11, end_lineno=3, end_col_offset=16), lineno=3, col_offset=4, end_lineno=3, end_col_offset=16)
BinOp: BinOp(left=Name(id='x', ctx=Load(), lineno=3, col_offset=11, end_lineno=3, end_col_offset=12), op=Add(), right=Constant(value=1, lineno=3, col_offset=15, end_lineno=3, end_col_offset=16), lineno=3, col_offset=11, end_lineno=3, end_col_offset=16)
Name: Name(id='x', ctx=Load(), lineno=3, col_offset=11, end_lineno=3, end_col_offset=12)
Load: Load()
Add: Add()
Constant: Constant(value=1, lineno=3, col_offset=15, end_lineno=3, end_col_offset=16)
Name: Name(id='int', ctx=Load(), lineno=1, col_offset=24, end_lineno=1, end_col_offset=27)
Load: Load()
Assign: Assign(targets=[Name(id='a', ctx=Store(), lineno=6, col_offset=0, end_lineno=6, end_col_offset=1)], value=Constant(value=2, lineno=6, col_offset=4, end_lineno=6, end_col_offset=5), lineno=6, col_offset=0, end_lineno=6, end_col_offset=5)
Name: Name(id='a', ctx=Store(), lineno=6, col_offset=0, end_lineno=6, end_col_offset=1)
Store: Store()
Constant: Constant(value=2, lineno=6, col_offset=4, end_lineno=6, end_col_offset=5)
Expr: Expr(value=Call(func=Name(id='plus_one', ctx=Load(), lineno=7, col_offset=0, end_lineno=7, end_col_offset=8), args=[Name(id='a', ctx=Load(), lineno=7, col_offset=9, end_lineno=7, end_col_offset=10)], lineno=7, col_offset=0, end_lineno=7, end_col_offset=11), lineno=7, col_offset=0, end_lineno=7, end_col_offset=11)
Call: Call(func=Name(id='plus_one', ctx=Load(), lineno=7, col_offset=0, end_lineno=7, end_col_offset=8), args=[Name(id='a', ctx=Load(), lineno=7, col_offset=9, end_lineno=7, end_col_offset=10)], lineno=7, col_offset=0, end_lineno=7, end_col_offset=11)
Name: Name(id='plus_one', ctx=Load(), lineno=7, col_offset=0, end_lineno=7, end_col_offset=8)
Load: Load()
Name: Name(id='a', ctx=Load(), lineno=7, col_offset=9, end_lineno=7, end_col_offset=10)
Load: Load()